
六爻预测股市公式 让股神巴菲特退位!我用深度学习做了个神经网络模型,可以预测出股市的涨跌走势!
六爻预测股市公式 让股神巴菲特退位!我用深度学习做了个神经网络模型,可以预测出股市的涨跌走势!
想象一下,如果您知道股票何时上涨或下跌,然后将所有资金投入或做空该股票,您会不会成为股票神话和百万富翁? !

不幸的是,这是不可能的,因为没有人知道未来。但是我们可以根据我们现在和过去任何股票的信息做出估计的猜测和有根据的预测。基于过去股价走势和模式的猜测称为技术分析。我们可以使用技术分析来预测股票的价格方向,但这并不是 100% 准确的。事实上,一些交易者批评技术分析,称其在预测未来时与占星术一样具有欺骗性。但也有人相信技术分析并最终取得一些成功。
在我们的示例中,我们将使用的神经网络将使用技术分析来进行股市预测。我们将实现的具体神经网络称为循环神经网络 - LSTM。
多变量输入
由于我们构建的最后一个 RNN 只能使用一个序列(过去的收盘价)来预测未来,我们想看看是否可以向神经网络添加更多数据。也许这些其他数据可以改善我们的价格预测?也许通过向我们的数据集添加指标,神经网络可以做出更准确的预测?这正是我们接下来要做的。
在接下来的几节中,我们将构建一个新的循环神经网络,它不仅可以接收技术分析指标形式的一条信息,还可以接收技术指标形式的多条信息,以预测股票市场的未来价格。
价格历史和技术指标
为了使用神经网络预测股市,我们将使用 SPDR S&P 500 (SPY) 的价格。这将使我们对股票市场有一个全面的了解,并且通过使用 RNN,我们或许能够确定市场的走向。
我们需要下载历史价格记录
要为我们的神经网络检索正确的数据,您需要访问 Yahoo 并下载 SPY 价格。为方便起见,我们将下载 SPY 的五年历史价格。 csv 文件。
下载:/quote/SPY/?p=SPY
技术指标
下载SPY的价格历史后,我们可以应用技术分析库生成技术指标值。
编码神经网络
导入库
让我们导入一些库并开始编写我们的神经网络代码:
# 导入库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from datetime import timedelta
from sklearn.preprocessing import RobustScaler
plt.style.use("bmh")
# 技术分析库
import ta
# 神经网络库
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
# 加载数据
df = pd.read_csv("SPY.csv")首先,我们导入一些常用的库(numpy等)。接下来六爻预测股市公式 让股神巴菲特退位!我用深度学习做了个神经网络模型,可以预测出股市的涨跌走势!,我们导入了之前用于创建 BTC 技术指标的技术分析库(在上面的文章中有介绍)。然后,我们从 Keras 导入神经网络库。导入必要的库后,我们将加载我们从雅虎财经下载的 spy.csv 文件。
预处理数据
## 日期时间转换
df['Date'] = pd.to_datetime(df.Date)
# 设定索引
df.set_index('Date', inplace=True)
# 删除任何NaNs
df.dropna(inplace=True)
## 技术指标
# 添加所有指标
df = ta.add_all_ta_features(df, open="Open", high="High", low="Low", close="Close", volume="Volume", fillna=True)
# 除“关闭”和指标以外的所有内容
df.drop(['Open', 'High', 'Low', 'Adj Close', 'Volume'], axis=1, inplace=True)
# 仅使用最近1000天的数据来更准确地表示当前的市场环境
df = df.tail(1000)
## 缩放比例
# 分别按比例调整收盘价以用于反向转换
close_scaler = RobustScaler()
close_scaler.fit(df[['Close']])
# 归一化/缩放DF
scaler = RobustScaler()
df = pd.DataFrame(scaler.fit_transform(df), columns=df.columns, index=df.index)日期时间转换
加载数据后,我们需要进行一些预处理,以便为神经网络准备数据,我们需要做的第一件事就是将数据帧的索引转换为格式。然后我们将数据中的日期列设置为DF的索引。
创建技术指标
接下来,我们将使用 ta 库创建一些技术指标。为了尽可能多地进行技术分析,我们将使用库提供的所有指标。然后,从数据集中删除除指标和收盘价之外的所有其他因素。
近期数据
创建技术指标值后,我们可以从原始数据集中删除一些行。我们将只包含最后 1000 行数据,以更准确地反映当前的市场状况。
缩放数据
在扩展我们的数据时,有多种方法可以确保我们的数据仍然准确表示。尝试使用不同的缩放器,看看它们如何影响模型性能。
在本例中,数据将使用 .这样做是为了使极端异常值几乎没有影响,并有望提高训练时间和整体模型性能。
辅助功能
在开始构建神经网络之前,让我们创建一些辅助函数来更好地优化过程。接下来我将详细解释每个功能。
def split_sequence(seq, n_steps_in, n_steps_out):
"""
Splits the multivariate time sequence
"""
# 为两个变量创建一个列表
X, y = [], []
for i in range(len(seq)):
# 查找当前序列的结尾
end = i + n_steps_in
out_end = end + n_steps_out
# 如果超出数据集的长度,则跳出循环
if out_end > len(seq):
break
# 将序列分为:x =过去的价格和指标,y =未来的价格
seq_x, seq_y = seq[i:end, :], seq[end:out_end, 0]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
def visualize_training_results(results):
"""
Plots the loss and accuracy for the training and testing data
"""
history = results.history
plt.figure(figsize=(16,5))
plt.plot(history['val_loss'])
plt.plot(history['loss'])
plt.legend(['val_loss', 'loss'])
plt.title('Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.show()
plt.figure(figsize=(16,5))
plt.plot(history['val_accuracy'])
plt.plot(history['accuracy'])
plt.legend(['val_accuracy', 'accuracy'])
plt.title('Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.show()
def layer_maker(n_layers, n_nodes, activation, drop=None, d_rate=.5):
"""
Creates a specified number of hidden layers for an RNN
Optional: Adds regularization option - the dropout layer to prevent potential overfitting (if necessary)
"""
# 使用指定数量的节点创建指定数量的隐藏层
for x in range(1,n_layers+1):
model.add(LSTM(n_nodes, activation=activation, return_sequences=True))
# 在每第N个隐藏层之后添加一个Dropout层(“ drop”变量)
try:
if x % drop == 0:
model.add(Dropout(d_rate))
except:
pass
def validater(n_per_in, n_per_out):
"""
Runs a 'For' loop to iterate through the length of the DF and create predicted values for every stated interval
Returns a DF containing the predicted values for the model with the corresponding index values based on a business day frequency
"""
# 创建一个空的DF以存储预测
predictions = pd.DataFrame(index=df.index, columns=[df.columns[0]])
for i in range(n_per_in, len(df)-n_per_in, n_per_out):
# 创建滚动间隔以预测
x = df[-i - n_per_in:-i]

# 使用滚动间隔进行预测
yhat = model.predict(np.array(x).reshape(1, n_per_in, n_features))
# 将价值变回其正常价格
yhat = close_scaler.inverse_transform(yhat)[0]
# DF存储值并稍后追加,频率使用工作日
pred_df = pd.DataFrame(yhat,
index=pd.date_range(start=x.index[-1],
periods=len(yhat),
freq="B"),
columns=[x.columns[0]])
# 更新预测DF
predictions.update(pred_df)
return predictions
def val_rmse(df1, df2):
"""
Calculates the root mean square error between the two Dataframes
"""
df = df1.copy()
# 添加带有第二个DF收盘价的新列
df['close2'] = df2.Close
# 降低NaN值
df.dropna(inplace=True)
# 添加另一列,其中包含两个DF的收盘价之间的差额
df['diff'] = df.Close - df.close2
# 求和并求均值
rms = (df[['diff']]**2).mean()
# 返回均方根的平方根
return float(np.sqrt(rms))-- 此函数拆分多变量时间序列。在我们的例子中,输入值将是股票的收盘价和指标。这会将值拆分为 X 和 y 变量。 X 值将包含过去的收盘价和技术指标。 y 值将包含我们的目标值(仅限未来收盘价)。 --这个函数将帮助我们评估我们刚刚创建的神经网络。在评估 NN 时,我们正在寻找的是收敛性。损失和准确性的验证值和常规值必须随着训练的进行而开始对齐。如果它们不收敛六爻预测股市公式 让股神巴菲特退位!我用深度学习做了个神经网络模型,可以预测出股市的涨跌走势!,则可能表示过拟合/欠拟合。我们必须回过头来修改神经网络的构造,这意味着改变层/节点的数量六爻预测股市公式,改变优化器函数等等——这个函数构造了神经网络的主体。在这里,我们可以自定义层数和节点数。它还具有正则化选项,可在必要时添加层以防止过度拟合/欠拟合。 () -- 此函数创建一个具有特定日期范围的预测值的 DF。每个循环向前滚动范围。范围的间隔是可定制的。我们使用这个 DF 来评估模型的预测,稍后将其与实际值进行比较。 -- 此函数将返回模型预测值与实际值之间的均方根误差 (RMSE)。返回的值表示我们的模型平均预测该值的程度。总体目标是减少模型预测的均方根误差。拆分数据
为了正确格式化我们的数据,我们需要将数据分成两个序列。这些系列的长度可以修改六爻预测股市公式,但我们将使用过去 90 天的值来预测未来 30 天的价格。然后,该函数会将我们的数据格式化为适当的 X 和 y 变量,其中 X 包含过去 90 天的收盘价和指标,y 包含未来 30 天的收盘价。
# 回顾过去90天的股市
n_per_in = 90
# 可以预测未来多少的股市
n_per_out = 30
# 特征
n_features = df.shape[1]
# 将数据分成适当的顺序
X, y = split_sequence(df.to_numpy(), n_per_in, n_per_out)我们的 NN 将使用这些信息来了解过去 90 天的收盘价和技术指标值如何影响未来 30 天的收盘价。
神经网络建模
现在我们可以开始构建我们的神经网络了!以下代码是我们如何使用自定义层和节点构建 NN。
##创建NN
# 实例化模型
model = Sequential()
# 激活
activ = "tanh"
# 输入层
model.add(LSTM(90,
activation=activ,
return_sequences=True,
input_shape=(n_per_in, n_features)))
# 隐藏层
layer_maker(n_layers=1,
n_nodes=30,
activation=activ)
# 最终隐藏层
model.add(LSTM(60, activation=activ))
# 输出层
model.add(Dense(n_per_out))
# 模型汇总
model.summary()
#使用选定的规范编译数据
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])
## 适配与训练
res = model.fit(X, y, epochs=50, batch_size=128, validation_split=0.1)这就是我们开始测试参数的原因:
必须研究我们为每个参数输入的值,因为每个值都可能对整体模型的质量产生重大影响。可能有一些方法可以找到每个参数的最佳值。
可视化损失和准确性
训练结束后六爻预测股市公式,我们将使用自定义辅助函数来可视化神经网络的进度:
visualize_training_results(res)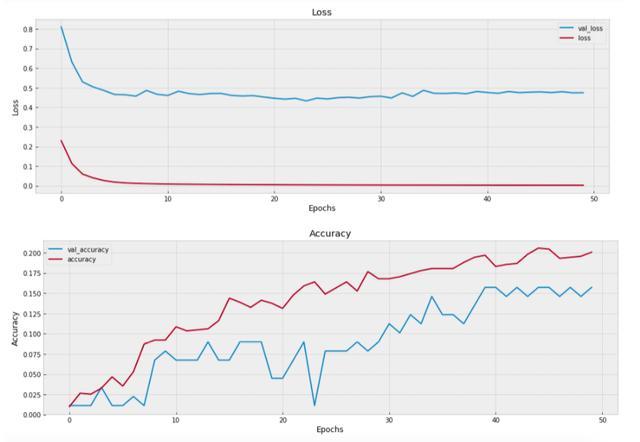
随着我们的网络被训练,我们可以看到损失在减少并且准确率在增加。通常,随着 epoch 数量的增加,我们希望两条线会聚或对齐。如果不符合要求,说明模型不足,需要回去修改一些参数。
模型验证
我们评估模型预测质量的另一种方法是对照实际值进行测试,并使用我们的自定义辅助函数来计算 RMSE。
# 将实际值转换为原始价格
actual = pd.DataFrame(close_scaler.inverse_transform(df[["Close"]]),
index=df.index,
columns=[df.columns[0]])
# 获取预测值的DF以进行验证
predictions = validater(n_per_in, n_per_out)
# 打印RMSE
print("RMSE:", val_rmse(actual, predictions))
# 绘图
plt.figure(figsize=(16,6))
# 绘制预测图
plt.plot(predictions, label='Predicted')
# 绘制实际值
plt.plot(actual, label='Actual')
plt.title(f"Predicted vs Actual Closing Prices")
plt.ylabel("Price")
plt.legend()
plt.xlim('2018-05', '2020-05')
plt.show()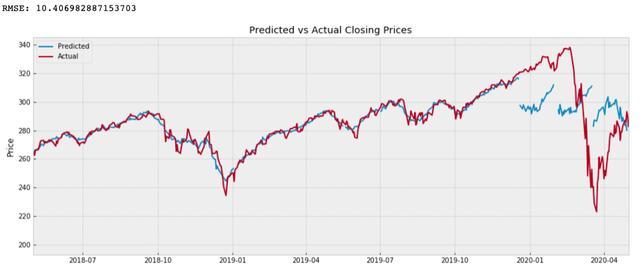
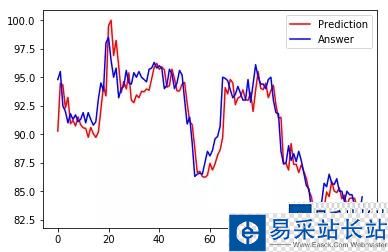
在这里,我们将预测值与实际值进行对比,以查看其对比情况。如果预测值与实际值相差甚远,而与实际值非常接近,那么我们就知道我们的模型有缺陷。但是,如果值看起来很接近并且 RMSE 较低,那么我们可以得出结论,我们的模型是可以接受的。
我们的模型起初似乎表现良好,但它无法捕捉或模拟价格的剧烈波动。这可能就是为什么最后三个预测看起来如此遥远的原因。也许通过更多的训练和实验,我们的模型可以预测这些行为。
预测股市的未来
一旦我们对模型的表现感到满意,我们就可以用它来预测股市的未来走向。
# 根据原始DF预测最近几天
yhat = model.predict(np.array(df.tail(n_per_in)).reshape(1, n_per_in, n_features))
# 将预测值转换回其原始格式
yhat = close_scaler.inverse_transform(yhat)[0]
# 创建预测价格的DF
preds = pd.DataFrame(yhat,
index=pd.date_range(start=df.index[-1]+timedelta(days=1),
periods=len(yhat),
freq="B"),
columns=[df.columns[0]])
# 返回绘制实际值的周期数
pers = n_per_in
# 将实际值转换为原始价格
actual = pd.DataFrame(close_scaler.inverse_transform(df[["Close"]].tail(pers)),
index=df.Close.tail(pers).index,
columns=[df.columns[0]]).append(preds.head(1))
# 打印预测价格
print(preds)
#绘图
plt.figure(figsize=(16,6))
plt.plot(actual, label="Actual Prices")
plt.plot(preds, label="Predicted Prices")
plt.ylabel("Price")
plt.xlabel("Dates")
plt.title(f"Forecasting the next {len(yhat)} days")
plt.legend()
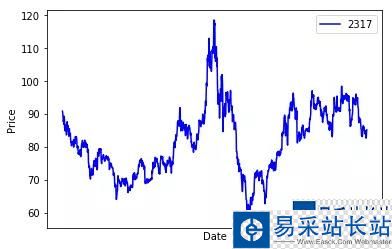
plt.show()这里,我们只是根据下载的.csv文件中的最新值进行预测。运行代码后,我们得到如下预测:
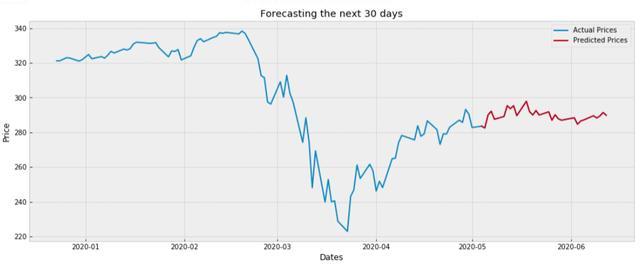
我们终于有了 SPY 的预测价格。你可以用这些知识做你想做的事,但请记住:股市是不可预测的。这里的预测值是不确定的。它们可能比我们的随机猜测要好一些,因为这些只是基于过去技术指标和价格模式的有根据的猜测。
最后
我们能够成功构建一个能够接受多个输入的 LSTM 层循环神经网络。模型的质量可能因人而异,这取决于他们想在模型上花费多少时间。这些预测对于想要深入了解股票未来价格走势的人很有用,即使他们无法预测未来。相信这样的方式会比我们随机猜测的更好。
现在玩! (技术是有风险的,亏了就别找作者了,哈哈哈哈,仅供技术人员学习!)
--END--
喜欢这篇文章的同学,记得转发+收藏哦~
主题测试文章,只做测试使用。发布者:佚名,转转请注明出处:https://jiemeng.link/liuyao/292.html
